Basics 04 - Functions (Part 1)
Love and hate relationship with programming. Always learning programming and Jazz.
Functions - The heart and soul of any functional programming language.
What's so special about functions? That's the question I asked myself when I started exploring functional programming languages. I came from a C/C++/C# background. For me, functions were not so special. Functions were where I placed the logic, passed some parameters, and got some output. Functions helped me break down bigger "things" into smaller "things." Some extreme cases involved function pointers in C, or delegates in C# for callbacks/hooks. That is it...
Real or Impure World and Pure World
Before we begin discussing functions and what's so special about functions and functional programming languages, let's establish a contract, a thought process to break down applications (full-blown projects or modules or anything sizeable) into two parts: Real or Impure World and Pure World.
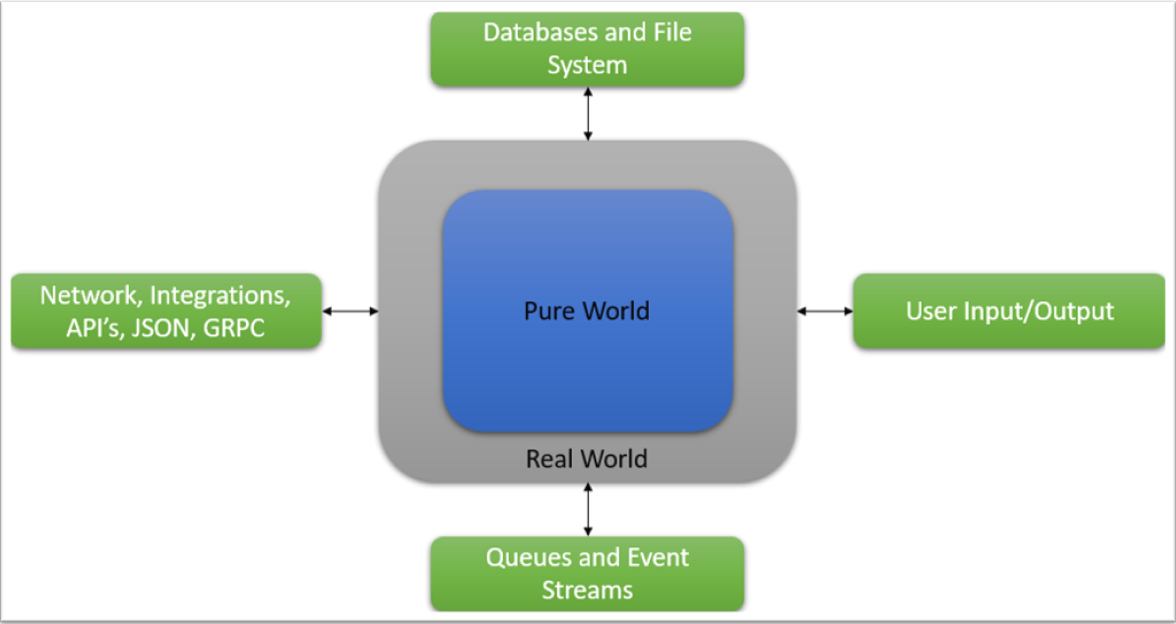
Real/Impure World deals with:
Databases and file system
Queues and event stream
User input/output
Network, integrations and APIs etc.
Essentially anything which has "uncertainty"
Pure world deals with only one thing:
The business logic, the core purpose of the application/module
Essentially anything which has "certainty"
Let's take a simple example. You need to write an application that does the following:
Start
Read a JSON file from the filesystem
Parse JSON
Perform validations
Apply transformations
Create new JSON
Write new JSON to the filesystem
Log (to the filesystem) success/failure
Stop
Now let's breakdown the application scope into two worlds:
Real/Impure World: Reading/Writing JSON, Logging
Pure World: JSON parsing (deserialization), JSON creation (serialization), Validations, and Transformations
Once you have the breakdown:
Implement the real/impure world
Implement the pure world
Figure a way out to stitch the two together
For the remainder of this section, we will focus on the pure world only.
The Pure World - The World of Pure Functions
Let's take some examples of functions written in C#:
public static string MyToUpper(string s)
{
return s.ToUpper();
}
public static string CombineStringAndCurrentDate(string s)
{
Log($"CombineStringAndCurrentDate called with {s}.");
return $"{s}-{DateTime.Now}";
}
Problems with MyToUpper function from the caller's perspective:
What happens if
nullis passed? Does it crash/throw or return an empty string?If it returns an empty string in case of failure/crash, how does the caller differentiate between empty input vs. crash case?
Is this function internally calling ToUpper or ToUpperInvariant?
Problems with CombineStringAndCurrentDate function from the caller's perspective:
Nearly all the problems with
MyToUpperfunction, the uncertainty/ambiguityIs the current date prefixed or postfixed?
What format of DateTime (to string) is used?
Why is this function logging? Who asked for it?
Now let's define what a pure function is. Remember that we are in the pure world, where we implement the business logic, the real purpose of the application. Some of these ideas presented here may seem unrealistic to you, as they did to me. Be patient and keep reading, slowly everything should make sense.
A pure function should not deal with
nullorvoid; you should never think of these terms in the pure world; absence of data has a better representationA pure function should not deal with exception handling; there are no thrown/caught exceptions; similar to
null/voidfor the absence of data, failures have a better representationA pure function should not deal with Global State; it operates purely locally; that is, it operates only on the parameters that are supplied to it (see below for more details on Global State)
Similar to point no. 3, a pure function has no Side Effects (see below for more details on Side Effects)
If you combine point no. 3 and 4, a pure function does exactly what the scope/purpose is, nothing more or less
In continuation to point no. 5, a pure function, ideally, does just one thing
And lastly, given the same input, a pure function should ALWAYS produce the same output
At this point, you may wonder what meaningful piece of code can be written if these guidelines are followed. Yes, I wondered the same. I couldn't wrap my imperative and OOP mind around these ideas. As I said earlier, be patient and keep reading, slowly everything should make sense.
Let's discuss a few more areas and then we should get back to pure functions.
Global State and Side Effects
These are two terms you will often encounter in the world of functional programming, or wherever functional ideas are borrowed in the imperative world (React.JS for example). There are all sorts of twisted explanations available for the global state and side effects. Let's have a simple view. Simple views are helpful.
The Global State is anything that's outside the scope of a function.
Typical examples are:
Some global (application/module level) look-up table (dictionary/map etc.) or list or queue is read/written from functions
Reading system date/time
Filesystem reading/writing (console printing, reading user input from the console and logging etc.)
The list goes on...
All of these are examples of a function going (for reading or writing) outside the boundary of its parameters. Too many problems are caused by this behavior. The biggest challenge is synchronization. If a function is reading the global state, you have to ensure it's not reading stale or out-of-sync values. If a function is writing/changing the global state, you have to ensure that the change is broadcasted to others. If broadcasting is not possible (as it's not the easiest to implement), you are forced to use locks for synchronization.
Side effects, simply put, are what functions cause when they write/change the global state. If a function is not writing/changing the global state it cannot have a side effect. As simple as that.
Rule to remember: a function should perform only within the boundary of its parameters.
Inversion of Control (IoC)
This is a very old idea, sadly, now marketed as "Dependency Injection." Buried under marketing, a plethora of libraries, and fancy documentation, the real philosophy is lost.
Let's understand what inversion of control means with the help of this example written in C#:
static void PrintTodayDateTime()
{
Console.WriteLine($"Current date and time is {DateTime.Now}.");
}
Here's a function that prints the current date and time. Everything works fine. Time passes by, more and more requirements come and you realize the following:
This function prints the message in a fixed format, there is no way to change it. If you change the implementation of this function, what about all the existing functionality that depends on the current implementation of it?
This function converts DateTime to string in one way only (
DateTime.Now.ToString()actually). If we add a parameter to control the conversion ofDateTimetostring, the existing code will break.This function only prints the current date and time. Now there is a new demand to print past/present/future DateTime values. You will have to create new functions for newly discovered use cases or change the existing function and break existing code.
The answer to all these problems is: to allow a function to assume as little as possible, aka inversion of control. Here is the same function written with all previously mentioned problems fixed:
static void PrintDateTime(string format, DateTime dateTime, string dtFormat)
{
Console.WriteLine(string.Format(format, dateTime.ToString(dtFormat)));
}
// Different callers
PrintDateTime("Current date and time {0}.", DateTime.Now, "D");
PrintDateTime("{0} is the current date and time.", DateTime.Now, "U");
Inversion of control simply means that the caller of function has control. The called function simply operates within the boundary set by the caller. Inversion of control allows you to write reusable, generalized functions, which are called with the right parameters, and those parameters are the problem of the caller.
Pure Functions are Look-up Tables
Imagine a pure function written in F#:
let add2Nums x y = x + y
Here are the results of invoking add2Nums with various values of x and y:
| X | Y | Result |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 2 | 4 | 6 |
| 8 | 10 | 18 |
| 100 | 1000 | 1100 |
Now imagine a Dictionary declared in F#:
let dictionary = Dictionary<(int * int), int>()
The key in this dictionary is a tuple (int * int), and the value is an int. Imagine you have populated the dictionary like this:
dictionary.Add((1, 0), 1)
dictionary.Add((1, 1), 2)
dictionary.Add((1, 2), 3)
For key, you pass 2 numbers, and for value, you pass the sum of those 2 numbers. And once you have populated this dictionary with infinite values, you can look up the sum of any 2 numbers.
Now what's the difference between invoking add2Nums for x and y, and looking up dictionary for (x, y)? In theory, there is no difference. You should get the same result.
While creating such lookup tables makes no sense, this example should help you understand a key idea: calling a pure function is the same as performing a lookup.
The Beauty of Pure Functions
Pure functions, when combined with techniques like IoC, partial application, chaining, and pipelining, allow you to:
Write reusable, generalized functions
Write functions that have no ambiguity, no uncertainty
Write composable functions, that is, compose bigger functionality by stacking smaller pieces of functions
Conclusion
This was just an introduction to pure functions. Now we need to focus on techniques, how to achieve IoC, partial application, chaining, pipelining etc. Once we discuss these topics, we will revisit Pure World, and how to compose functions.
If you have reached so far, congratulations.
Keep reading!